
A NeurIPS 2024 Blog: Day 0 & Day 1
Published:
Hello there 👋 Attending large machine learning conferences is both exciting and challenging. They can be expensive and not accessible to everyone, and I’ve certainly felt the fear of missing out when unable to attend in the past. That’s why I want to share a first-person account of my experiences at the conference. Think of this as a bi-daily diary that brings a little bit of the conference to you.
Before heading out, I did some preparation—though probably not as much as I should have. I checked my presentation slots, reviewed the tutorials, and made a very rough selection of interesting papers to explore. But as someone wise (basically everyone) has told me, at some point, conferences become more about the people than anything else 😉. That thought brings me some relaxation amidst the whirlwind of events.
This year feels very different. It’s my first NeurIPS since working full-time, and there’s so much happening beyond just absorbing knowledge. There are numerous venture capital dinners, collaboration meetings, and even indirect recruitment opportunities. It’s a lot to take in, but also incredibly exhilarating.

Day 0: Monday – Travel Day ✈️
My journey began with a flight from Berlin to Vancouver via Amsterdam. The plane was filled with fellow NeurIPS attendees. I always feel a bit anxious in these situations. On one hand, I’m eager to chat and connect; on the other, I sometimes feel overwhelmed by the sheer number of potential interactions.
During the flight, I struck up a conversation with a research scientist from NXAI. We the discussed the European start-up ecosystem and the broader trends in the ML community. Upon landing, I randomly bumped into Edoardo Cetin - a fellow Sakana AI family member 0 at passport control. We ended up sharing a ride to the hotel, engaging in a deep science chat along the way. Talking about complex topics after 20 hours of travel is both fun and exhausting, but it set a great tone for the week ahead.
After a quick research meeting call to catch up on projects, I headed to the conference venue to pick up my registration materials. The venue was buzzing with activity, and it was exciting to see so many people gathered for the same purpose. I took some time to catch up on the recent Sora release and posted the obligatory “Hello NeurIPS world” tweet to let everyone know I’d arrived.
Looking forward to an exciting #NeurIPS2024 week and co-presenting DiscoPOP, JaxMARL & 2 workshop papers [details to follow]🎉
— Robert Lange (@RobertTLange) December 10, 2024
Reach out if you want to chat about Agentic Discovery 💡, the AI Scientist 👨🔬, Evolution 🧬 and @SakanaAILabs 🎏
💌 DMs are open & we are recruiting! pic.twitter.com/jMPGgQAl5v
If you’re curious about the work we’ll be presenting, you can find an overview here. Come and say hi!
Day 1: Tuesday - Tutorials & Opening Keynote 📝
On Tuesday, the first day of the conference dedicated to tutorials, I woke up at 4 AM — jet lag is real. I went to Horton’s for breakfast and noticed that bacon 🥓 seems to be much more of a thing here than in Berlin. Back at the hotel, I caught up on emails and watched an AMD documentary covering Lisa Su’s tremendous path and AMD’s positioning within the “AI Race” (you can watch it here). I started setting up the notes and homepage for the blog; I haven’t done this in a while, and I’m excited to share some thoughts. Amidst all this, I had to squeeze in some coding and prepare slides for upcoming research meetings.
Tutorial Session I: Flow Matching 🎨
I watched the first tutorial on Flow Generative Models from my bed. The slides are available here. Being entirely new to diffusion and flow matching, I found it really exciting.
Flow Matching is a scalable method for training flow generative models by regressing a velocity field. For sampling, you simply follow the velocity. Starting with a sample $X_0$ (like noise), the model learns to map it to $X_t$ using an iterative process via a parameterized continuous-time Markov process. Essentially, it involves learning this transition function.
Compared to diffusion and jump processes — which are slower and have a larger design space —flows are simple and fast. In Flow Matching, the parametrization as velocity represents the probability flow. The forward process involves solving ordinary differential equations (ODEs), while the backward process uses differentiation. Velocities are linear objects, offering computational advantages. Second-order solvers like the Midpoint method work particularly well for sampling.
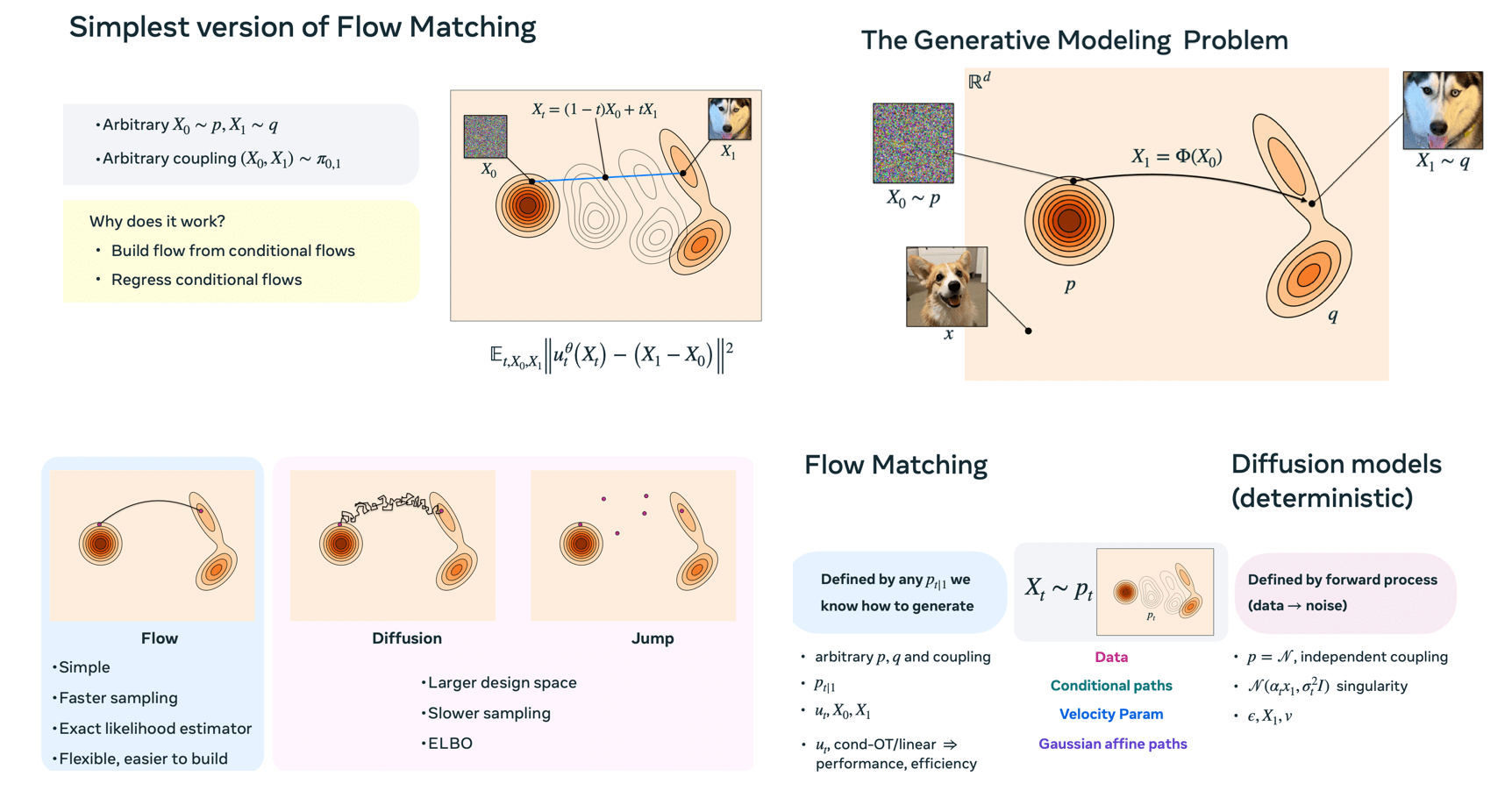
The Flow Matching loss is straightforward, akin to performing regression or minimizing a Bregman divergence. Minimizing this loss is related to optimal transport by minimizing kinetic energy. An advantage over diffusion models is that flows avoid issues related to the singular Gaussian nature of diffusion processes.
Advanced designs in Flow Matching include conditioning and guidance, where labels or classifier is used to condition the source distribution. This allows the generative model to train on various conditions, even without explicit guidance methods. Another area is data couplings, which involves altering the source distribution instead of adding a condition. Approaches like using paired data (ground truth and noisy versions) or multisample couplings.
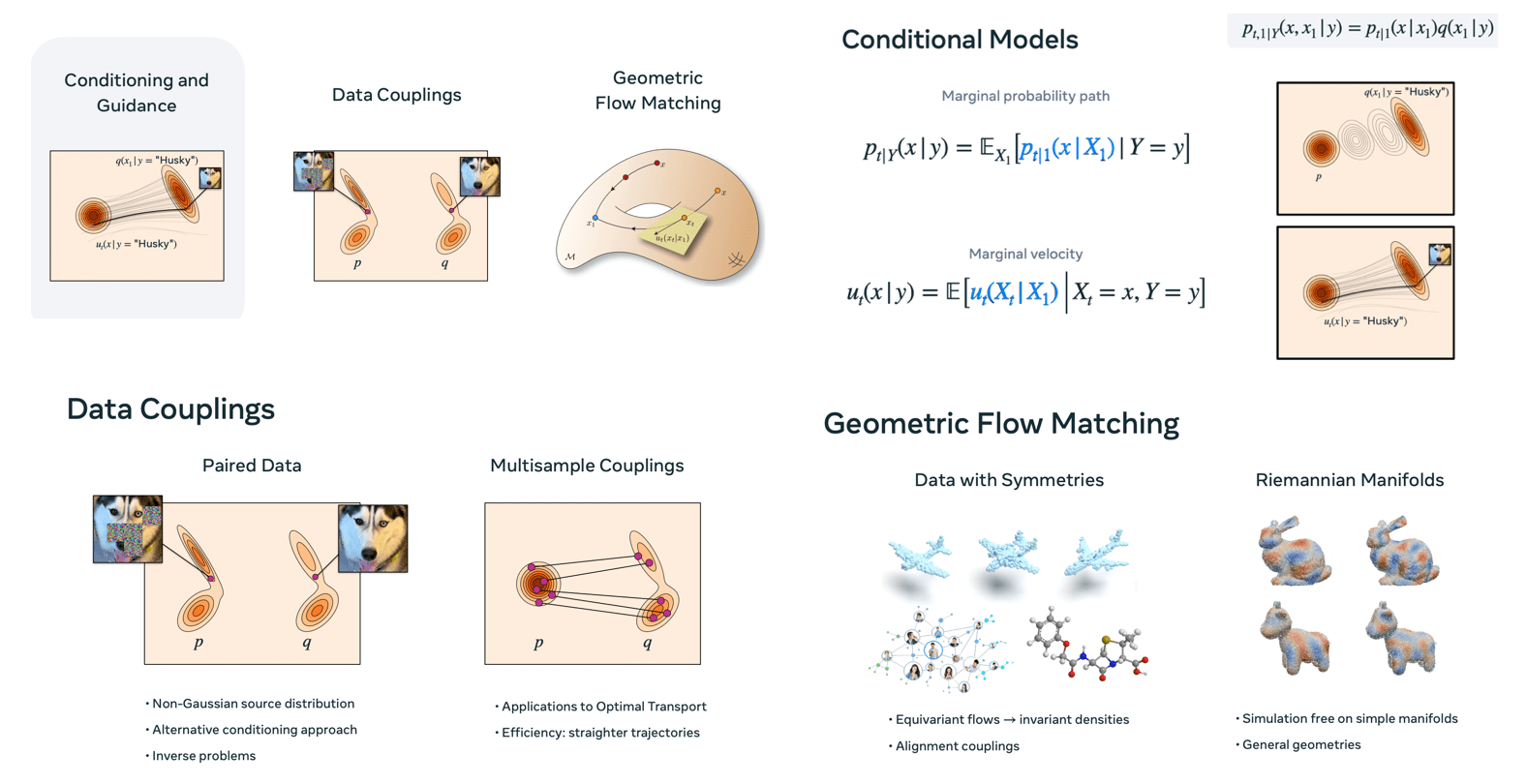
Geometric Flow Matching addresses data with symmetries by enforcing invariances under data transformations. Equivariant flows lead to invariant probability paths. For data on Riemannian manifolds — common in scientific fields like robotics or climate science — we need to redefine the geometric structures from Euclidean space by using Riemannian metrics and selecting suitable pre-metrics with geodesics.
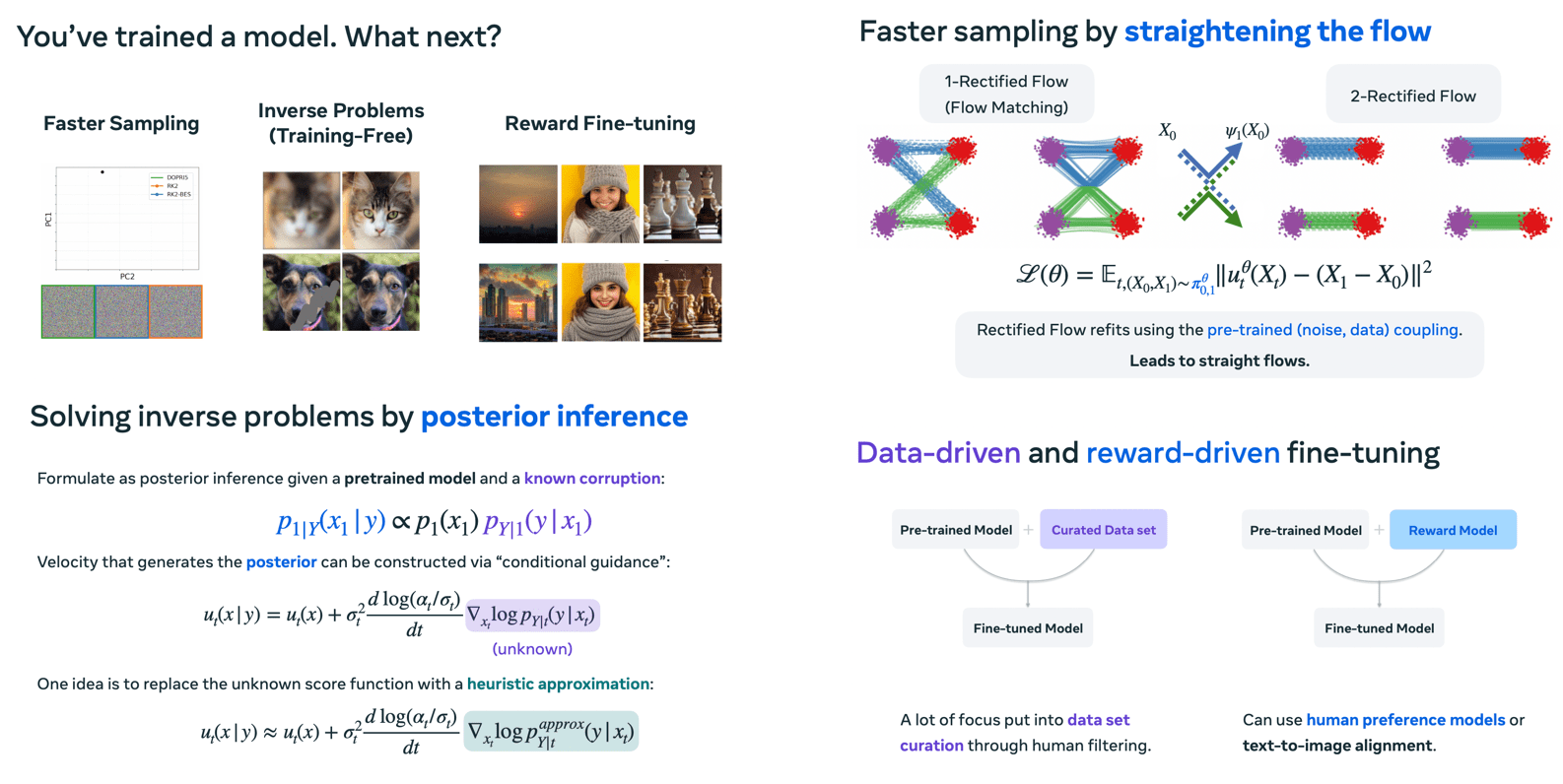
When it comes to model adaptation after training, faster sampling can be achieved by straightening the flow through rectification, which disentangles sampling paths and induces optimal transport. This might restrict the model and reduce capacity, though. Self-consistency loss, a type of self-distillation, ensures that two small steps are equivalent to one large step, introducing an auxiliary loss that enhances consistency. Modifying the solver through scale and time transformations allows for disentangling the model from the solver and optimizing the solver’s parameters. This optimized solver can then be transferred to another model, potentially even one trained on an entirely new dataset.
After the tutorial, I headed to the conference site and had dinner with Tan Charakorn, whom I’d worked with during his Sakana AI internship. Connecting in person with people you’ve only worked with remotely is one of my favorite parts of the conference experience.
Tutorial II: Meta-Generation Algorithms for LLMs 💬
The second tutorial I attended focused on how to generate outputs from a large language model (LLM), exploring different techniques for test-time computation. These techniques include extra token generation, such as the chain-of-thought method; extra generator calls, exemplified by AlphaCode-style approaches; and extra models or tools, leading to compound AI systems. All tutorial materials are available here: Meta-Generation Algorithms Tutorial.
Loving the #NeurIPS2024 'Beyond Decoding: Meta-Generation Algorithms for LLMs' workshop ❤️ by @wellecks @mattf1n @haileysch__:
— Robert Lange (@RobertTLange) December 10, 2024
1. Primitive generators: optimization vs sampling
2. Meta-generators: chain, parallel, tree, refinement
3. Efficiency: quantize, FA, sparse MoEs, KV… pic.twitter.com/Syg0jqTw3I
1. Primitive Generators: Single Sequence
One approach involves treating decoding as optimization, where approximate probability maximization can often yield better results. Methods like greedy decoding and beam search (with narrow beam sizes) are used, although beam search can fall into repetition traps and may require penalties, length normalization, or handling atypicalities. Another method is decoding as sampling, using techniques like truncation sampling (top-k, top-p) and temperature shaping of the distribution. Additionally, constraint decoding or structured decoding can enforce specific output formats. For instance, JSON schema enforcement employs finite state machines for masking or templating the sampling distribution, while token healing addresses tokenization issues that arise during templating.
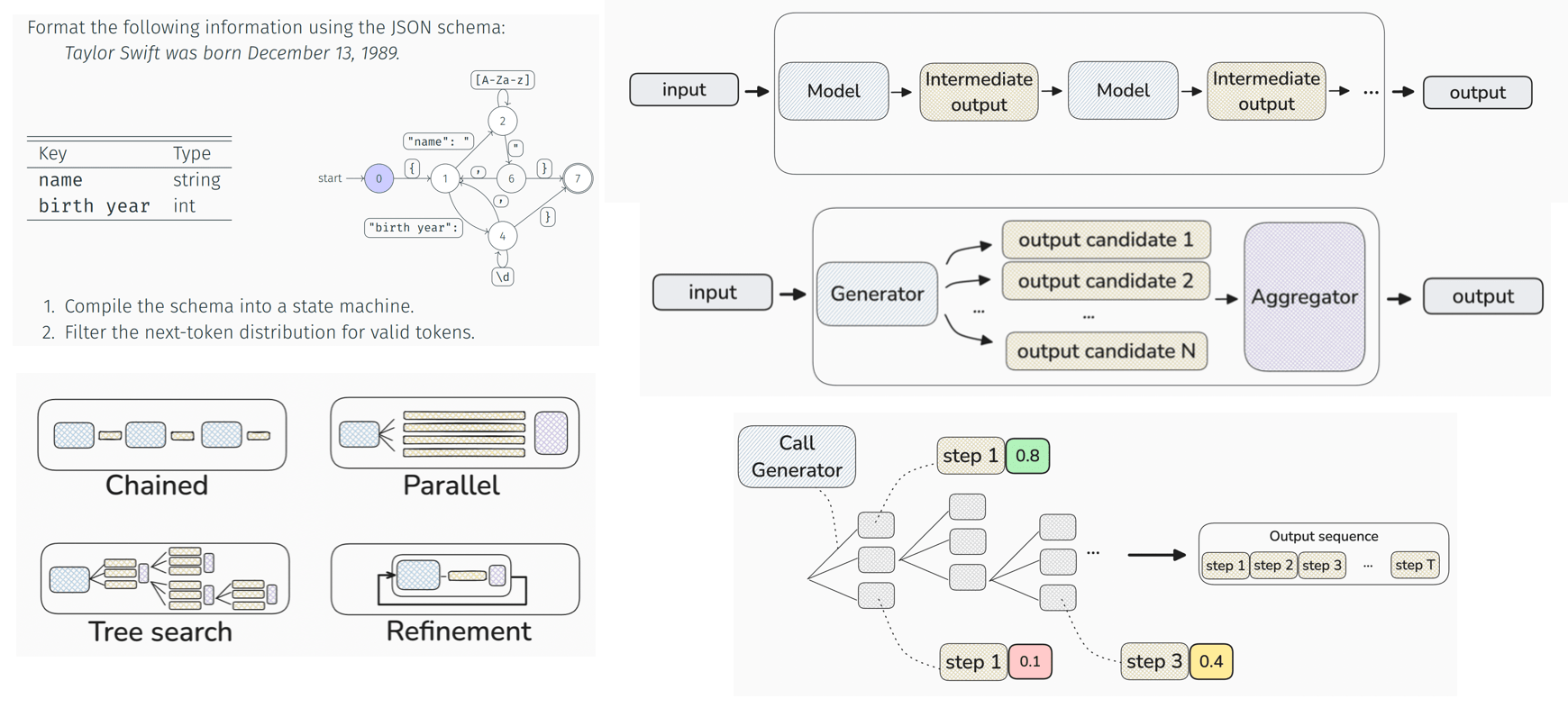
2. Meta-Generators: Treating LLM as a Black Box
This approach treats the LLM as a black box and uses tools to assess the acceptability of its outputs, such as a reward model or critic (e.g., Lean for theorem proving). Several strategies are employed. Chain methods, like chain-of-thought, increase capacity by functioning like an external tape. This can involve integrating a search engine, creating LLM cascades, or developing LLM programs. Parallel generation techniques—such as best-of-N sampling, rejection sampling, majority voting, or weighted voting with a reward model—are used, with the reward model applied only at the end of the generation process. In tree search, an evaluator assesses intermediate generation steps using process-based reward models (RPM) or reward-balanced search (Rebase), allowing backtracking and exploration based on intermediate scores but requiring a suitable environment and value function. Refinement and self-correction involve external feedback tools for verification or intrinsic feedback through re-prompting or a trained corrector. When scaling meta-generation, optimal compute allocation is crucial; selecting the best trade-off between model size, number of tokens, and strategy is essential for efficiency.
3. Efficient Meta-Generation
The tutorial also delved into the essentials of efficient meta-generation, focusing on factors like latency, throughput, and quality trade-offs. Techniques for optimizing these aspects were discussed, emphasizing the importance of balancing computational resources with performance requirements to achieve optimal results. Key hardware considerations include VRAM, FLOPS (operations performed during forward passes), and memory bandwidth (needed for loading inputs and weights). Strategies such as batching and key-value (KV) caching—distinguishing between the prefill and decode stages—play significant roles in enhancing performance.
For single token sampling speed-ups, reducing memory bandwidth is crucial. Methods like quantization help by reducing the amount of data transferred. Increasing FLOPS through improved hardware utilization, exemplified by techniques like FlashAttention, can accelerate computations. Conversely, reducing the number of required operations (reducing FLOPS) using sparse Mixture-of-Experts (MoEs) models is another effective approach.
When it comes to single generation speed-ups, which are typically memory-bound, techniques like speculative decoding are employed. This involves using a draft model to generate proposal tokens and a larger model for rejection sampling. The effectiveness of this method often depends on the specific problem and the context length.
To accelerate the meta-generation process itself, several strategies are used. Shared prefix cache reuse allows multiple sequences to benefit from common initial computations. RadixAttention, which utilizes a tree structure of KV cache blocks, improves efficiency by organizing data hierarchically. Additionally, KV cache compression—through token dropping, quantization, or architectural modifications like grouping queries—can significantly reduce memory requirements.
Alison Gopnik: The Golem vs. Stone Soup
Gopnik is well-known for her extensive work on children’s cognitive development, particularly how young minds learn about the world through exploration, play, and social interaction. Her research delves into how children form theories, understand causality, and develop the foundations of knowledge—often likening their learning processes to those of scientists. She began her talk with two mystical stories and one sci-fi story.
Story 1 – The Golem (1635): In this tale, the Golem and the Rabbi of Prague, a magician gives life to matter, creating an agent-like being. The story doesn’t end well and doesn’t accurately represent the current state of AI, but the Golem serves as a metaphor for the public’s perception of artificial intelligence.
Story 2 – Stone Soup (1548): Here, a magician creates magical soup from stones for a village. As villagers contribute additional ingredients, everyone ends up participating in making the soup. This mirrors AI development: while we have AI, it requires data, algorithmic improvements, prompt engineering, and compute power—the collective contributions of the community debunk the notion of a lone magician.
Story 3 – ‘The Lifecycle of Software Objects’ by Ted Chiang: Unlike the previous tales, there are no magicians here. AIs are depicted as babies that need to learn and are adopted by humans who become attached. As these agents quickly surpass humans, their human caregivers must figure out how to let their AI “children” grow and move into the world.
Gopnik emphasized that the secret to human intelligence goes beyond the central nervous system. There’s a vast social system—such as caretakers—that allows babies to safely explore and discover the world. Turing’s 1950 AI paper also calls for simulating the child’s mind rather than the adult’s, prompting us to consider what we can learn from the developmental processes of children. She argued that there’s no such thing as “general intelligence,” natural or artificial. Instead, there are many intelligences with associated trade-offs: exploitation (maximizing utility), exploration (maximizing truth), and transmission (maximizing convergence).
Transmission intelligence involves sharing knowledge of things we know to be true. This concept is central to the stone soup interpretation of AI’s current state. Large models, as cultural technologies, have built upon numerous stepping stones like language, art, and the internet, as well as norms, rules, regulations, and laws. These elements have been digitized, making information organization easier through standardization. Throughout history, changes in cultural technologies—such as the printing press—have transformed the world by enhancing transmission intelligence.
On the other hand, exploration intelligence is about discovering something new. It encompasses noisiness, risk-taking, impulsivity, play, and curiosity—all traits we typically associate with children. Gopnik proposed the hypothesis that “childhood is evolution’s way of resolving the explore/exploit trade-off and performing simulated annealing.”
Delving into causal learning and exploration, she cited research by Goddu & Gopnik (2024), which shows that four-year-olds can perform sophisticated causal inference. Interventionist interactions, where intentional actions serve as proxies for interventions, suggest that causal learning can be viewed as Bayesian hypothesis testing. This raises questions about its relationship to reinforcement learning—specifically, whether versions of RL with intrinsic epistemic rewards exist. Gopnik cautioned against relying solely on information gain, as it can lead to endless exploration. Instead, she advocated for focusing on empowerment and controllability as intrinsic rewards.
Studies like Contingency Learning by Rovee-Collier (1972) demonstrate that babies use experimental programs to understand the world, seeking empowerment. Similarly, Love and Learning (Tottenham et al., 2019) found that non-stationary environments require exploration despite potential punishment; in rats, infants exhibit this exploration only in the presence of their mothers. The link between parental investment and learning is evident in comparisons between species like quokkas and possums—the larger the brain, the greater the parental investment.
Can we apply these insights to AI e.g. problems like the alignment of AI systems? Just as parents raise children who will live in environments different from their own, we face similar challenges with AI. Can we draw inspiration from human development to guide the creation and integration of AI systems?
Looking Ahead to Tomorrow 🌅
The day ended with an amazing dinner hosted by Sakana AI and Lux Capital. I had a wonderful time chatting with Grace Isford and my fellow AI scientists Cong Lu and Chris Lu, as well as talking to many people who are current and potential future Sakana fellows.
With the first poster sessions and oral presentations starting soon, it’s important to be prepared. Make sure to arrive early — last time at NeurIPS in Vancouver, entry to the poster sessions was blocked due to the number of attendees. Try to decide which posters you want to discuss with the authors and plan to skim and take notes on things you want to revisit later.
Connecting with others is key, so make sure to create new friendships 😉. At the same time, self-care is important. As someone who describes himself as neither extroverted nor introverted, I sometimes get overwhelmed. Stepping outside to grab some fresh air helps. And, of course, staying hydrated is essential — remember to drink enough water. Okay, enough of this paternalism for now.